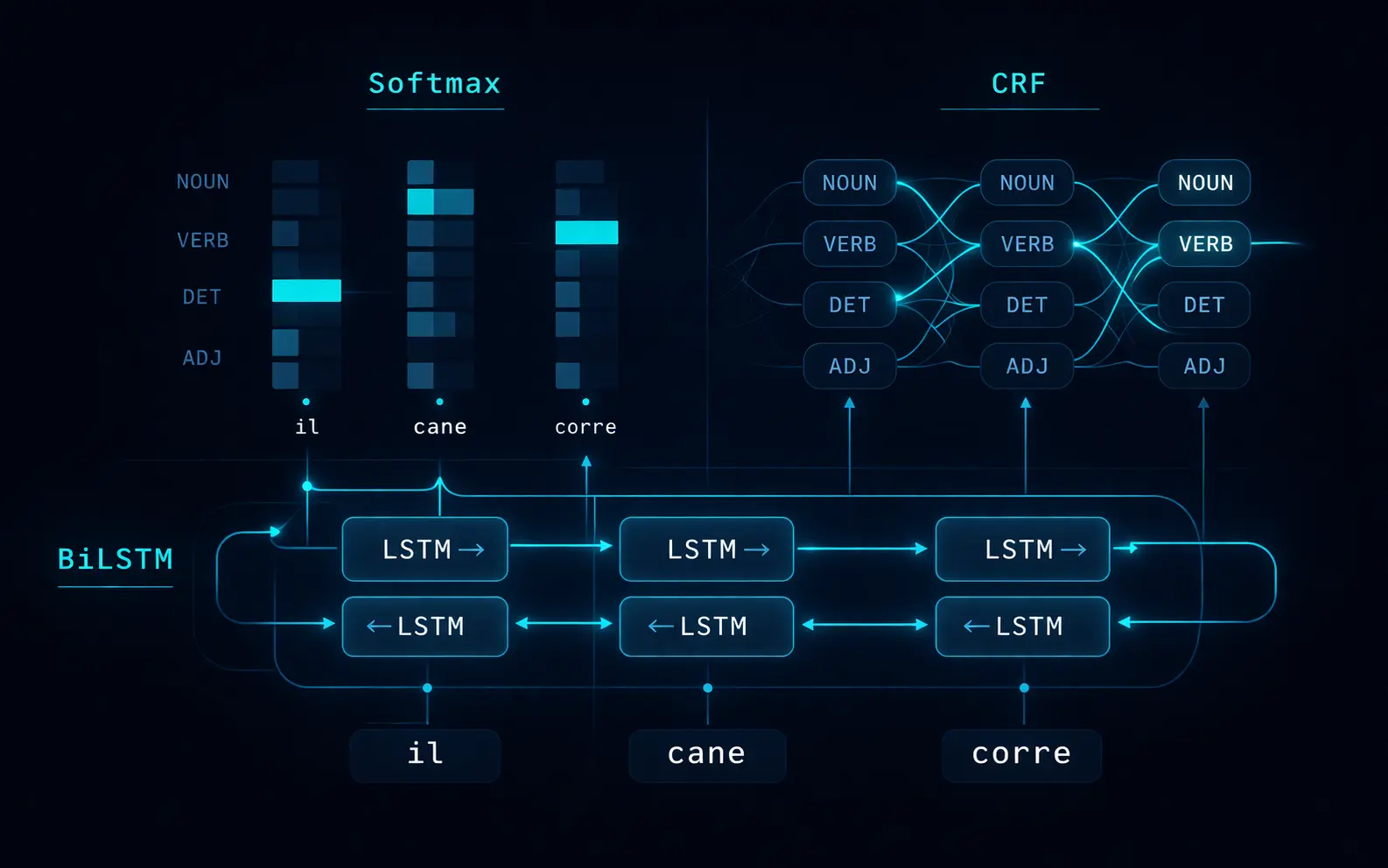
Overview
Part of speech (POS) tagging is the task of assigning a grammatical label to every word in a sentence. It is one of the foundational NLP tasks: accurate POS tags inform nearly every downstream task from parsing to information extraction.
This project trains and compares two sequence labelling models on the Italian EAGLES corpus. Both share the same BiLSTM backbone and FastText word embeddings; the only difference is in the output layer. The first model uses a standard Softmax classifier treating each token independently at decode time. The second replaces this with a Conditional Random Field (CRF), which models tag-to-tag transition probabilities and decodes the full sequence jointly using the Viterbi algorithm.